This is the time and place where I would want to talk about my experience on this course, #TC1019. Having Ken as our teacher taught me a lot of things about myself, and made me see things I considered normal and standard in a whole different scope. For all right and wrong, here’s my attempt at expressing all of it in video format:
Ken, thanks for everything. May our paths meet again someday.
I wish I knew as many song lyrics as you do so I could somehow make a pun out of this, but I just don’t. But as my last post this semester, I’ll just leave here a song I like very much that may fit this all… “The Last Song”:
Well… entropy is always increasing. Have you heard that before? 2nd Law of Thermodynamics. I like how Samuel Arbesman says it here: “everything is getting more complex and you can't get a handle on it. None of us can! Basically, no one knows what's going on”. He’s a complexity scientist, by the way.
You might consider yourself a pretty disordered person already, and let me tell you, you kind of have the Universe to thank for that! Let me try to explain…
Back to thermodynamics. Its 2nd law makes a very strong statement, but let me tell you: entropy refers to the number of combinations you can arrange small-scale particles and still have the same large-scale properties. Like trying to think of a tall brown dog that pees on the living room. There are lots of dogs (# combinations) like this, but they all have the same large-scale properties. Now, another important term: complexity. This refers to how hard it is to describe some set of large-scale properties.
The thing is, there comes a point in all systems in the Universe where both entropy and complexity go so high that things get so mixed together that it suddenly just doesn’t make sense to differentiate one part from the other. Therefore, its large-scale properties become easier to describe and complexity goes down. Entropy, however, continues going up. Always...
Graphs, please! It looks something like this:
So what does this all have to do with you and me? Everything. In fact, it’s only because of the point at which the Universe is currently in that you and me exist. How, you might wonder? Because you and me are living at the most exciting time of the Universe’s history, at the point of highest complexity and ever increasing entropy!
So, what happens after this complexity cusp of the Universe? NOTHING. Really, nothing. The universe will reach a point of high entropy and low complexity. All of us humans, complex structures, just won’t exist anymore. Nothing will, actually. All existence will be reduced to the simplest of all ways. And no, there’s nothing we can do about it. We can enjoy our beautiful high times of complexity right now, though!
This video does a lot better at explaining all this, please go take a look!
Hopefully, I left you as interested in complexity/entropy as I am :) I used these among my sources, feel free to dig any deeper:
First, perhaps the reason you came here for: who owns the Internet? NOBODY. Or rather, all of us...
Internet. We’re never away from it, not anymore. How else could you be reading this? Well, for that to be possible, a lot, a LOT of things have to happen. It’s really not just paying your bills to your Internet Service Provider (ISP. Oh, acronyms!).
Have I sparked a bit of curiosity in you yet? I hope, because it was that same curiosity spark that recently got me to enroll in a course on Internet Governance. Have you ever heard those 2 words together? I certainly hadn’t. I took this course for free thanks to www.internetsociety.org, I just had to create an account!
So, what did I learn from this course? First off, the term governance here doesn’t mean government(s) or the private sector. Not necessarily. To put it simply, let me list some of the things Internet Governance stands for:
Public Politics: content control, cybersecurity, cybercrime, intellectual property…
Standards…
Principles, norms, procedures…
That sure sounds interesting, right? Oh, for me it sure does! I dove deep into this course and I took a lot from it. The Internet’s an enormous, open, accessible platform. There are international associations and groups working day and night to make it possible for the Internet to be better than it is; international associations paying attention to all opinions from governments, companies, academies and of course, us! the civil society.
Not excited yet? Here’s the awesome part, then: I got a scholarship from Internet Society to attend this year’s Internet Governance Forum! An United Nations international multistakeholder event where issues pertaining Internet Governance will be discussed. Internet Society will be paying all expenses for me and several other people in Latin America, US and Europe. Why am I telling you all this? Because I would like to encourage you to get involved in this type of topics, there are tons of things to discover. And, you’ll be contributing to the development of the Internet we all want to see!
I’ve talked a bit more into this in the following 5min video. Hope you like it :)
What is open source, really? You might have heard it once or twice, but trust me: you’ve used open source software before (or at least I hope so). Let me dig a little deeper into this…
“Open source” means something that is modifiable by the people, something they can share with one another because its source design is publicly available. Doesn’t this sound awesome? It sure does for me. This whole term was born out of needs for software development, as an approach to creating computer programs. However, today we call projects done “the open source way” those that satisfy all following characteristics:
collaborative participation
rapid prototyping
transparency
meritocracy
community-oriented development
The SOURCE term we’ve been using refers to the part of the software that most users don’t see. It’s what a programmer can manipulate to make tangible changes on how a software works. This makes it possible to add new features or fix something! Who could be better testers, than your everyday users?
So, what do I call all the other software I’ve been using my whole life? Most certainly, you should be calling it “proprietary”, or “closed” software. With these types of software, only their authors can legally copy, inspect and alter it. You know all those terms and conditions you’ve agreed before? Those enormous texts you surely haven’t read… Well, that’s what you have to do when you use proprietary software; you agree to not doing anythings with the software that isn’t expressly permitted by their authors. You don’t need to go too far, do you recognize anny of these logos?
Yeah… Microsoft Office and Adobe Photoshop are just perfect examples of proprietary software!
Are you wishing there existed some open source version of these types of software? Well wish no mre! Here’s one I found: LibreOffice
It’s the perfect alternative for Microsoft Office, but with the beauty of “to open source way”!
Well, what about Photoshop? Beware, there’s an open source alternative too! It’s called GIMP. Go ahead and take a look: https://www.gimp.org/
Please, before you leave, make sure you don’t have the common misconception of open source just meaning free of charge! Yes, all open source software I just mentioned is free, but don’t be surprised if you find an open source software that’s not free. This is completely possible. Sorry :(
It all depends to what the programmers are trying to accomplish, and how lucrative an opportunity they find. Don’t forget that skill in programming and troubleshooting open source software can be quite valuable. At the end of the day, we all have to make a living for ourselves.
Title might seem too self explanatory (I thought that too), but no. Not necessarily. There’s more to this than what you might assume by just knowing what it’s called.
For what I’ve come to learn, correct me if I’m wrong, when you talk about software implementation you’re talking about the challenges a development team faces when implementing software. This, in terms of making the team work as one and that all code seems to have been written by the same person. This makes it a whole easier to understand what another member of your team is doing, how you can contribute, and measure the overall progress of your team because you all basically have the same way of organizing yourselves.
Let me go deeper into this…
These challenges I mentioned before are among these classifications:
code-reuse: a lot of problems arise when you’re faced with compatibility issues when trying to re-use code from somewhere else. And when trying to solve this, you’ll then have to think: HOW MUCH actual code should I re-use?
Version Management: It doesn’t matter if a new version of your software is released, you should never throw away all documentation you have on previous versions and configurations! You’ll want to go back at some point and check for something, you never know… That’s why you need your documentation to be highly accurate and descriptive.
Target-host: Yes. At times it’s going to be impossible to design a single piece of software that runs flawlessly on every user machine, but your design should still aim for that! The way you implement software should consider the multiple environments in which your software will exist.
Hopefully, you’re seeing the connection this all has with previous blog I’ve written about. Software implementation is deeply correlated with testing and architecture, for example. Or at least that’s how I’ve come to understand it :) You can read more about it in my other blog posts. And for reading any further int othe sources I used for writing this, here it is:
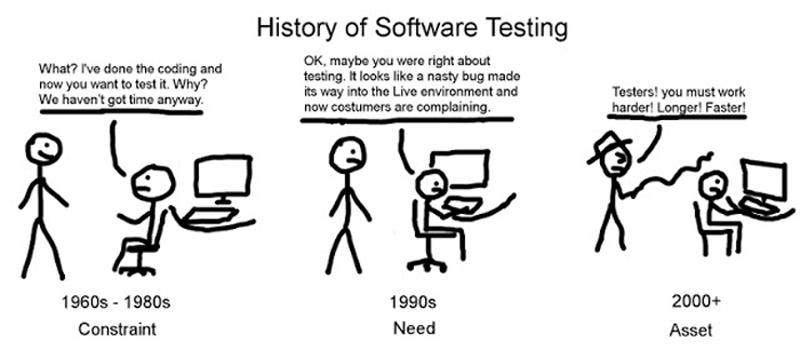
Title’s pretty self explanatory. Or, is it? software testing…
This can be a very fun process. You’re basically trying to break things from all possible angles. Find bugs and you’ve done your work correctly. Of course, the software development team’s work just doubled! Or maybe backstepped all the way.
Your responsibilities as a software tester are verifying and validating that a program, application or product pass all following tests:
meeting business and technical requirements upon which design and development were constructed (You see where everything I’ve talked about design and requirements in other blog posts gets us to?)
working as expected
possible implementation on multiple environments and use cases
No easy work, that’s for sure. If some bug gets to the users, not only will the software development team be approached, but software testers as well. Why wasn’t the bug discovered during testing?
Before I go any further, aren’t you wondering why computer bugs are called BUGS? I sure was... What does the world have against bugs? Poor animals. Well, back in the day computers were as large as classrooms, actual real-life, living bugs were a huge problem in these monstruous computers. You got rid of the bug, you got rid of a problem on your program. Funny how these terms stick through history, right?
Perhaps I’ll be saying this in every blog from now on, but in a previous blog post, I talked about the Software Lifecycle. Remember? Please do :( Software testing is an essential part of the SDLC. It is at this point (no matter the methodology) that you might find bugs that will throw you back some steps of the development process. Fix those bugs, test again, and pray it all goes well.
You might want to think about some types of software testing:
Static testing can find bugs without executing code! It’s done during verification process. Documents and source code are reviewed. All this in terms of walkthrough, inspection, etc.
Dynamic testing includes actual execution of the code. It’s done during validation process. All this in terms of unit testing, integration, system testing, etc.
You surely do tests all day long, for everything. In fact, everything you know now is surely only the conclusions upon which you have arrived after doing some tests of validity (hopefully). I mean, don’t you try several clothes on before leaving your house? try several keys for your door before finding the right one? try that new food on the menu? In BIG terms, everything you’re doing in your life right now is a big testing you do on yourself to see if what you’re doing makes you a happy person. You’re a professional tester already. You might not be that far from being a software tester… These were the coolest sources I found for the information I present here: http://istqbexamcertification.com/what-is-a-software-testing/ http://www.codeproject.com/Tips/351122/What-is-software-testing-What-are-the-different-ty
Go have fun testing your path through life in search for happiness :)
I didn’t know what these were, either. After some research, I’ll now try explaining to you what I learned. Sounds good to you?
Again, this has a very continuous relationship with previous topics I’ve talked about before. Specially, you’ll find yourself thinking of software architecture (hopefully). Why? For starters, design patterns are something a software architect should always be able to identify. Let me too you why…
There are some reusable, optimized solutions to common programming problems. Solutions that people who build programming languages should also identify right away. This solutions I’m talking about are, in fact, design patterns. But all these people must be careful: “If implemented in the wrong place, it can be disastrous and create many problems for you. However, implemented in the right place, at the right time, it can be your savior”. (source)
It’s important to know there are basically 3 types of design patterns:
Structural
Creational
Behavioral
Their names don’t say much, do they?
Structural patterns refer to relationships, how entities work together.
Creational patterns refer to the way mechanisms are instantiated, so each situation has its easiest way of object-creation.
Behavioral patterns refer to the communication between entities (please do not confuse these with structural patterns).
What I mean by “patterns” is basically past situations other programmers have been through. They’ve experienced the same, and now they know a solution for it. Why wouldn’t you want to consider their way of solving these problems?
Let me include a very illustrative result:
Imagine something like this in code-form. How many interfaces do you see? several. But on the other side, in how many ways is this thing reacting to the several interfaces? One. Just one! This is precisely one example of the adapter pattern: “structural design pattern that allows you to repurpose a class with a different interface, allowing it to be used by a system which uses different calling methods”. How COOL is that? This one and some other examples can be found here: https://code.tutsplus.com/articles/a-beginners-guide-to-design-patterns--net-12752
One last thing before you go: ALWAYS make sure the solution you’re working with is actually meant for particular problems like your own. Hopefully you won’t ever find yourself in a situation where you learn this the hard way.